Network Architecture¶
Introduction¶

Federated Machine Learning is a distributed machine learning approach. In its simplest form it is composed of one Coordinator and a set of Participants.
The Coordinator is responsible for keeping any state required for the machine learning task, orchestrate the machine learning task across a set of Participants, and perform the Aggregation of the individual updates returned by the Participants.
The Participants are mostly stateless processes that receive from the Coordinator a global model and the machine learning task to execute. Once they finish executing the machine learning task they return the updated model to the Coordinator.
Federated Machine Learning Flow¶
Instantiate a Coordinator with the task to execute the number of clients required and the number of rounds to perform (and any other relevant information)
# warning: updated since time of writing - do not attempt to run!
$ xain-coordinator fashion_mnist_100p_IID_balanced --clients=20 --rounds=50
Instantiate the Participants with the Coordinator address. If the Coordinator is not reachable just periodically try to reconnect.
# warning: updated since time of writing - do not attempt to run!
$ xain-client ec2-198-51-100-1.compute-1.amazonaws.com --port=5000
Rendezvous
- Once all necessary Participants are connected, start a round:
Coordinator sends global model
Participants run the training
Participants send the updates (and any other relevant information)
- Coordinator completes a round:
Wait for all Participants updates
Run the Aggregation on the individual updates
Repeat 4 and 5
- If any Participant gets disconnected during a round:
Wait for new Participants to come back online until the necessary number of clients is met
Resume the task
Once all rounds are completed the Coordinator can just exit
Coordinator¶
This section discusses the design and implementation details of the Coordinator.
Requirements and Assumptions:
We need a bi-direction communication channel between Participants and Coordinator.
There is no need for Participant to Pariticipant communication.
The Pariticipants run on the client infrastructure. They should have low operation overhead.
We need to be agnostic of the machine learning framework used by the clients.
Keep in mind that the Coordinator may need to handle a large number of Participants.
Features that need to be provided by the Coordinator:
Ability for Participants to register with it.
Ability for Participants to retrieve the global model.
Ability for Participants to submit their updated model.
Ability for the Coordinator to orchestrate the training.
Ability to keep track of the liveness of Participants.
gRPC and Protobuf¶
For the networking implementation we are using gRPC and for the data serialization we are using protobuf.
The Coordinator is implemented as a gRPC service and provides 3 main methods.
A Rendezvous method that allows Participants to register with a Coordinator. When handling this call the Coordinator may create some state about the Participant in order to keep track of what the Participant is doing.
A StartTrainingRound method that allows Participants to get the current global model as well as signaling their intent to participate in a given round.
An EndTrainingRound method that allows Participants to submit their updated models after they finished their training task.
In order to remain agnostic to the machine learning framework Participants and Coordinator exchange models in the form of numpy arrays. How models are converted from a particular machine learning framework model into numpy arrays are outside the scope of this document. We do provide the xain-proto python package that performs serialization and deserialization of numpy arrays into and from protobuf.
gRPC Implementation Challenges¶
1. Keeping track of Participant liveness
The coordinator is responsible for keeping track of its connected participants that may be performing long running tasks. In order to do that the coordinator needs to be capable to detect when a client gets disconnected. This does not seem to be easy to achieve with gRPC (at least not with the Python implementation).
From a developers perspective gRPC behaves much like the request response pattern of a REST service. The server doesn’t typically care much about the clients and doesn’t keep state between calls. All calls are initiated by the client and the server simply serves the request and forgets about the client.
This also means that there really isn’t much support for long standing connections. It’s easy for a client to check the status of the connection to the server but the opposite is not true.
gRPC does use mechanisms from the underlying HTTP and TCP transport layers but these are internal details that aren’t really exposed in the API. A developer can override the default timeouts but it’s not clear from the available documentation the effect they have. For more information check using gRPC in production.
Server-side timeouts configuration:
server = grpc.server(
futures.ThreadPoolExecutor(max_workers=10),
options=(
('grpc.keepalive_time_ms', 10000),
# send keepalive ping every 10 second, default is 2 hours
('grpc.keepalive_timeout_ms', 5000),
# keepalive ping time out after 5 seconds, default is 20 seoncds
('grpc.keepalive_permit_without_calls', True),
# allow keepalive pings when there's no gRPC calls
('grpc.http2.max_pings_without_data', 0),
# allow unlimited amount of keepalive pings without data
('grpc.http2.min_time_between_pings_ms', 10000),
# allow grpc pings from client every 10 seconds
('grpc.http2.min_ping_interval_without_data_ms', 5000),
# allow grpc pings from client without data every 5 seconds
)
)
Client-side timeouts configuration:
stub = Stub(
'localhost:50051', :this_channel_is_insecure,
channel_args: {
'grpc.keepalive_time_ms': 10000,
'grpc.keepalive_timeout_ms': 5000,
'grpc.keepalive_permit_without_calls': true,
'grpc.http2.max_pings_without_data': 0,
'grpc.http2.min_time_between_pings_ms':10000,
'grpc.http2.min_ping_interval_without_data_ms': 5000,
}
)
It’s also not clear how connections are handled internally. At least in the Python library when opening a channel no connection seems to be made to the server. The connection only happens when a method is actually called.
With the provided APIs from the server side we can only do any logic from within a method call.
From the python gRPC documentation there seems to be two ways that allow us to keep track of client connections from the server side is to have the client calling a method that never returns. From within that method the server can either:
Add callback to get notified when an RPC call was terminated:
def rpc_terminated_callback(context):
# do something with the context
def SomeMethod(self, request, context):
context.add_callback(lambda: rpc_terminated_callback(context))
# rest of the method logic
Periodically check if the rpc call is active:
def SomeMethod(self, request, context):
while context.is_active():
time.sleep(5)
# if we reach this point the client terminated the call
The problem with these approaches is that we need to block the gRPC method call in order to keep track of the connection status. There are two problems with these long standing connections: we are wasting server resources to do nothing, and we need to deal with the underlying gRPC connection timeouts as described above.
Ultimately we decided to just implement ourselves a simple heartbeat solution. The Participants periodically send a heartbeat to the Coordinator. If the Coordinator doesn’t hear from a Participant after a pre-defined timeout if just considers the Participant to be down and removes the Participant from it’s participant list.
Heartbeat:
def Heartbeat(self, request, context):
self.participants[context.peer()].expires = time.now() + KEEPALIVE_TIME
return PingResponse()
# in another thread periodically call/schedule
def monitor_clients(self):
for participant in self.participants:
if participant.expires < time.now() + KEEPALIVE_TIMEOUT:
# remove participant and perform any action necessary
2. Requests need to be initiated by the Participants
With gRPC since the Coordinator implements the gRPC server all calls need to be initiated by the client. So we will need for the Participant to implement some form of polling mechanisms to know when the Coordinator is ready to start a round. Again the same solutions as the previous point can be applied.
One solution would be to block during a method call until the Coordinator initiates a round.
The other solution that we eventually chose was to reuse the heartbeat mechanism to notify the Participants on when to start training. During the heartbeat messages the Coordinator advertises its state with the Participants. When the Participants see that a new round has started they can request the global model and start their training task.
Coordinator Logic Implementation¶
Internally the Coordinator \(C\) is implemented as a state machine that reacts to messages sent by Participants \(P\).
Let’s consider the basic lifecycle of state transitions in \(C\). Let \(N\) be the number of required participants.
Once \(C\) starts up, it’s in the STANDBY state and open for incoming connections from participants looking to rendezvous. Once \(N\) have been registered, a number of these are selected for a training round. To simplify for now, assume all \(N\) will participate.
Starting from \(i=0\), in the ROUND \(i\) state, \(C\) starts to accept requests (from the registered \(N\)) to start training for the \(i\) th round. Any further requests from late entrants to rendezvous are told to “try again later”. For any \(P\) that has started training, \(C\) will also accept a subsequent request of it having finished training. If there are dropouts, \(C\) goes back to STANDBY and only resumes ROUND \(i\) once registrations again reach \(N\).
Once all \(N\) have finished training the \(i\) th round, \(C\) collects together all the trained data and aggregates them, generating a new global model. It either increments the round to \(i+1\) and repeats, or if there are no more rounds to go, it transitions to the FINISHED state signaling the participants to disconnect.
Participant¶
Participants are the workhorses of the federated learning platform. One would expect them to be spending a significant portion of their time computing trained models. But what exactly should be communicated between Participant \(P\) and Coordinator \(C\) in a training round?
It helps to look at the following (simplified) code excerpt from the
single-machine “prototype” fl/Coordinator:
# note: code updated since time of writing but idea remains the same
def train_local(p, weights, epochs, epoch_base):
weights_update, history = p.train_round(weights, epochs, epoch_base)
metrics = p.metrics()
return weights_update, history, metrics
To do its training, \(P\) will invoke its own train_round function.
For this, it requires the following data (annotated with their types) from
\(C\)
weights: ndarrayepochs: intepoch_base: int
In return \(P\) sends back a pair of data
weights_update: Tuple[ndarray, int]history: Dict[str, List[float]]
After a train_round, \(C\) also needs from \(P\)
a metrics of type Dict[str, ndarray].
Note
It is worth bearing in mind that since we are working with gRPC, all service calls must be initiated by the client (as discussed above), i.e. \(P\). This is completely unlike the code excerpt above, where it is naturally \(C\) that calls \(P\).
Also since \(P\) in addition sends metrics at the end of a round, this and the updated model can just as well be sent in the same message thus minimising communication.
Training Round Data Messages¶
The above considerations lead to the following gRPC service definition for exchanging training data. The Coordinator exposes two service methods
rpc StartTrainingRound(StartTrainingRoundRequest) returns (StartTrainingRoundResponse) {}
rpc EndTrainingRound(EndTrainingRoundRequest) returns (EndTrainingRoundResponse) {}
where the request and response data are given as the following protobuf messages:
message StartTrainingRoundRequest {}
message StartTrainingRoundResponse {
xain_proto.np.NDArray weights = 1;
int32 epochs = 2;
int32 epoch_base = 3;
}
message EndTrainingRoundRequest {
xain_proto.np.NDArray weights = 1;
int32 number_samples = 2;
map<string, xain_proto.np.NDArray> metrics = 3;
}
message EndTrainingRoundResponse {}
Note that while most of the Python data types to be exchanged can be
“protobuf-erized” (and back), ndarray requires more work. Fortunately we
have the
xain_proto/np
project to help with this conversion.
Training Round Communication¶
The communication is summarised in the following sequence diagram. In a training
round, \(C\) is in the state ROUND. The selected participant
\(P\) is in the TRAINING state (see
Participant State Evolution). The first message by \(P\) essentially
kicks off the exchange. \(C\) responds with the global model weights
(and other data as specified in StartTrainingRoundResponse). Then
\(P\) carries out the training locally. When complete, it sends the updated
model weights_update (and other metadata) back. \(C\) responds with
an acknowledgement.
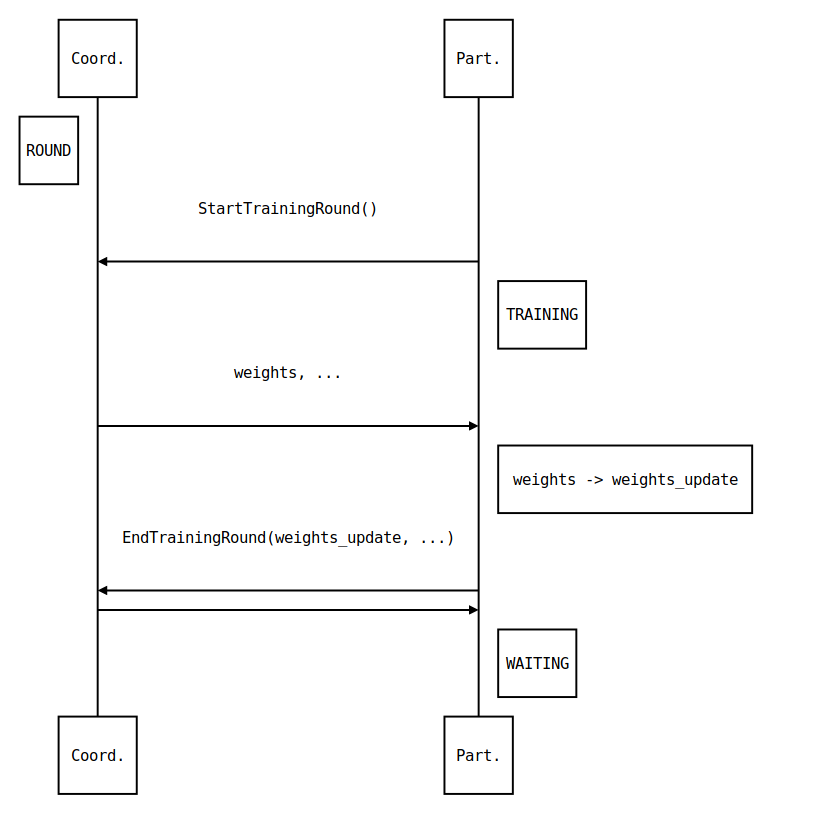
Participant Notification via Extended Heartbeat
In the above, how did \(P\) detect the state change in \(C\) to
ROUND given that there is no easy way for \(C\) to send such
notifications? As mentioned above in the discussion on the Coordinator, the
heartbeat mechanism was extended for this purpose. Not only does it provide a
liveness check on Participants, but it also doubles as a way for them to be
“signalled” (with some variable delay) of state changes.
In more detail, \(C\) now populates responses to heartbeats with either
ROUND (training round in progress) or STANDBY (not in progress) during a round.
In the former case, a round number is also emitted. When all rounds are over,
\(C\) will respond with FINISHED.
Participant State Evolution¶
The following is a description of the \(P\) state machine. It focuses on the state transitions in response to heartbeat messages described above, and is also able to handle selection.
In the WAITING \(i\) state, the idea is that \(P\) has already
trained round \(i\) locally and is waiting for selection by a ROUND
\(j\) heartbeat for \(j>i\). At this point, it transitions to
TRAINING \(j\). At the start, we initialise \(i=-1\).
In TRAINING \(j\), the idea is that local training for round \(j\) is in progress. Specifically, \(P\) carries out the above communication sequence of messages with \(C\):
StartTrainingRound\(\rightarrow\)weights\(\rightarrow\)weights_update\(\rightarrow\)EndTrainingRound
Having received the EndTrainingRound response from \(C\) signifying
the completion of this local round of training, \(P\) makes an “internal”
transition to WAITING \(j\).
If FINISHED is observed while WAITING, it moves to DONE.

